 Use of MAP_MERGE operator in HANA SQL
Use of MAP_MERGE operator in HANA SQL
For simplicity here we have taken the FLIGHT model tables as a part of example but in real when we deal with the high volume of data which can not processed by ABAP AS but in the AMDP with code push down. Here the main idea is to understand how the MAP_MERGE operator works in HANA SQL and relatively used a very small dataset.
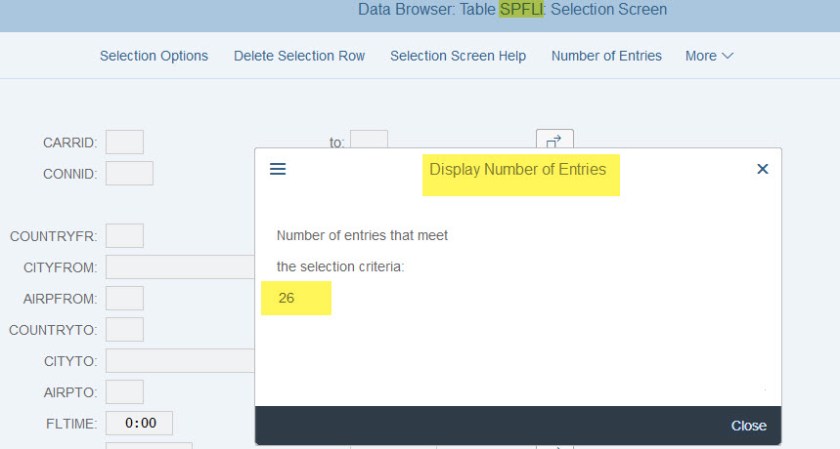
SCARR table contains 18 records and SPFLI contains 26 dependent records.

Below we have a class with two method-
One is AMDP procedure and another is AMDP function.
In the AMDP procedure we get all SCARR records and then we use the MAP_MERGE operator where we pass the input table and the mapper function.
We can get rid of the sequential loop here. What MAP_MERGE does, It does a parallelization of the input table records with currently available system resources and calls the mapper function and here the mapper function is the AMDP function to which carrid is passed and depended SPFLI record are received. And finally the result set is merged .
It is really fast and overcomes the sequential processing and one thing to be noted that each result set must be independent of one another.


We have the report to test the AMDP call.
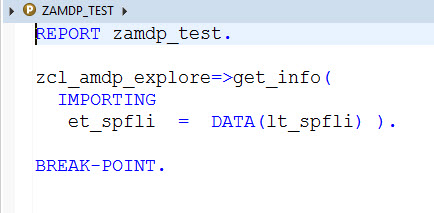
Debugger details.
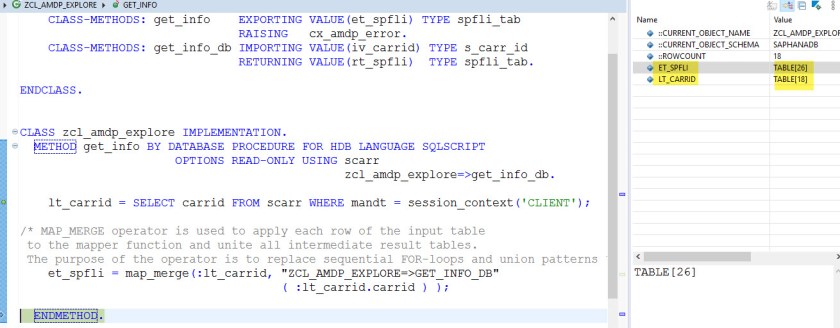
Debugger details.

